CheckMag | 没有 GPU,没问题。托管自己的 LLM 比大公司的审查产品有趣得多,而且效果出奇的好。

当你查询人工智能时,你的数据究竟会发生什么变化,谁也说不准,但无论发生什么变化,它肯定都不再属于你了。
与 图像和视频生成之外,如果你热衷于大型语言模型(LLM)的实验,但又不想把数据交给大型科技公司,那么托管自己的数据是一件非常容易的事情,而且与大型公司相比有很多优势。
首先,无论您选择用它来做什么,您的所有数据都在您的控制之下,如果您不想把数据交给Mechahitler,这一点就是立竿见影的优势。,这就是一个立竿见影的好处。您还可以使用几乎任何您喜欢的模型,无论是 Deepseek、Gemma2 还是 GPT,而且还可以使用不限制查询类型的版本。
KoboldCPP 是一款易于使用、可单次执行的人工智能文本生成工具,设计用于运行 GGUF 和 GGML 大型语言模型。它支持 GPU 和 CPU,可作为人工智能讲故事和聊天的专用后端。KoboldCPP 可从 GitHub下载,适用于 Windows、Linux、Mac OS 和 Linux。可用于 Windows、Linux、Mac 或 Docker。
通过在容器中托管,可以轻松地将 LLM 暴露给网络上的每台设备,而且还为包括 Unraid 和 TrueNAS 在内的主要平台预制了模板。只要在防火墙中添加必要的规则,其他安装方式也能实现同样的效果。
入门
一旦决定了所选的平台,就需要确定使用哪种模式。抱抱脸 是寻找模型的最佳地点,而且模型必须是 GGUF 格式。
如果您打算主持 D&D 场景,您肯定需要一个未经审查的模型,否则 LLM 最终会拒绝伤害任何角色,并可能产生不良结果。不良结果。
有些模型,如Deepseek和Claude等模型有 "思考 "倾向,基本上会将查询的整个思维过程都喷出来。如果使用 GPU 来完成繁重的工作,这种情况可能还好,但如果没有 GPU,处理速度就会大大降低。您必须尝试各种模型才能找到适合您的,但Gemma2是一个很好的开始。
找到文件页面,复制链接到 GGUF 文件的 URL。许多模型都有多种尺寸,因此您需要根据可用内存的限制来选择合适的尺寸。
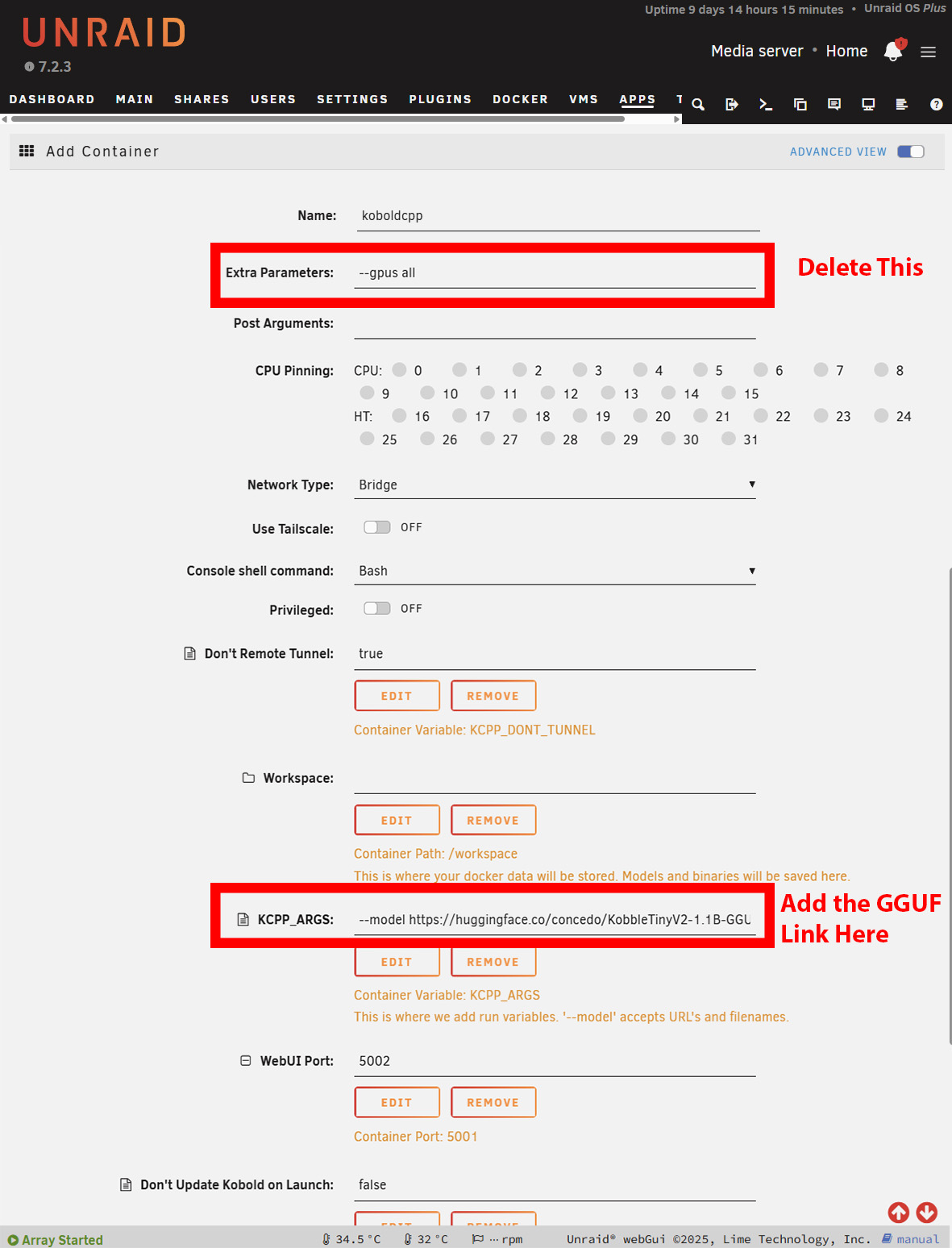
Windows 上的安装大致相同。不过,如果不使用 GPU,则需要下载NoCUDA版本。由于 KoboldCPP 会先下载模型,然后才显示界面,因此启动可能需要一些时间。在 Windows 上,这一点显而易见,但在 Unraid 或 TrueNAS 上,您必须打开日志才能看到下载进度。在 Unraid 上,您可能需要增加Docker 容器的可用存储空间,这取决于您选择的模型有多大。
KoboldCPP 提供 4 种不同的界面模式,包括指导、故事、聊天和冒险。
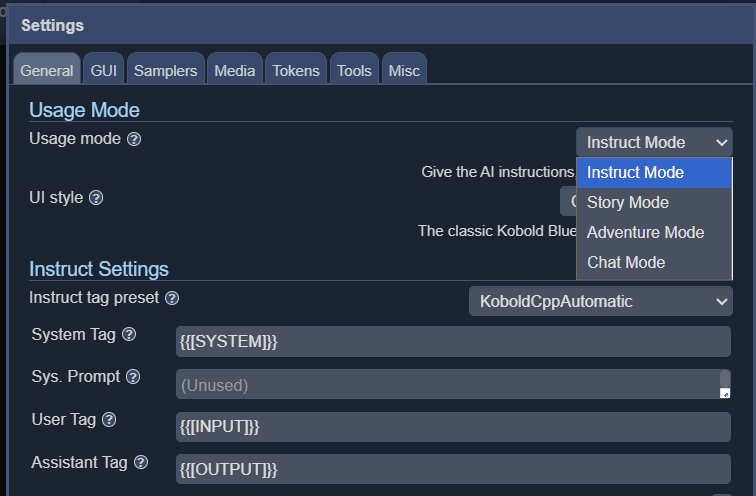
虽然速度不是最快的,但文本生成速度略低于平均阅读速度。在 16 核 AMD 5950x(亚马逊有售)上运行时,完全可以满足 D&D 场景的需要,在更现代的 CPU 上运行速度可能会更快。内核越多越好,内存越大越好,这样可以运行更大的机型,不过 16GB 应该没问题。机型的大小和类型也会对生成速度产生重大影响,选择更轻便的机型可以显著提高整体速度。
显然,要获得最佳体验,使用 GPU 运行大型语言模型是最佳选择,不过,如果您热衷于尝试托管自己的模型,绕过 ChatGPT、Claude 或 Gemini 的限制或数据隐私影响,您不需要任何高级硬件即可开始使用,而且还能获得不错的体验。
资料来源

