三星推出 TRUEBench,测试真实工作场景中的人工智能生产力
人工智能长期以来,人工智能基准一直在努力捕捉人们使用这些系统的实际操作。大多数测试仍然集中在纯英文的问答任务上,这些任务在纸面上看起来很整洁,但却无法反映日常工作中的各种活动。三星刚刚推出了https://news.samsung.com/global/samsung-introduces-truebench-a-benchmark-for-real-world-ai-productivityTRUEBench 是可信真实世界使用评估基准的简称,旨在以更接近真实办公任务的方式来衡量人工智能的性能。
TRUEBench 不局限于简单的琐事或单一提示交流,而是通过文档摘要、12 种语言的翻译、数据分析和需要人工智能保持上下文的多步骤指令来运行模型。三星开发了 2,485 个测试集,涵盖 10 个类别和 46 个子类别,输入内容从几个字符到两万多个字符不等。目标是模拟从快速命令到长篇商业报告的所有内容。
三星电子 DX 事业部首席技术官兼三星研究院院长 Paul (Kyungwhoon) Cheun 说:"三星研究院拥有深厚的专业知识,并通过其实际的人工智能经验带来了竞争优势。我们希望 TRUEBench 能够建立生产力评估标准,巩固三星的技术领先地位。
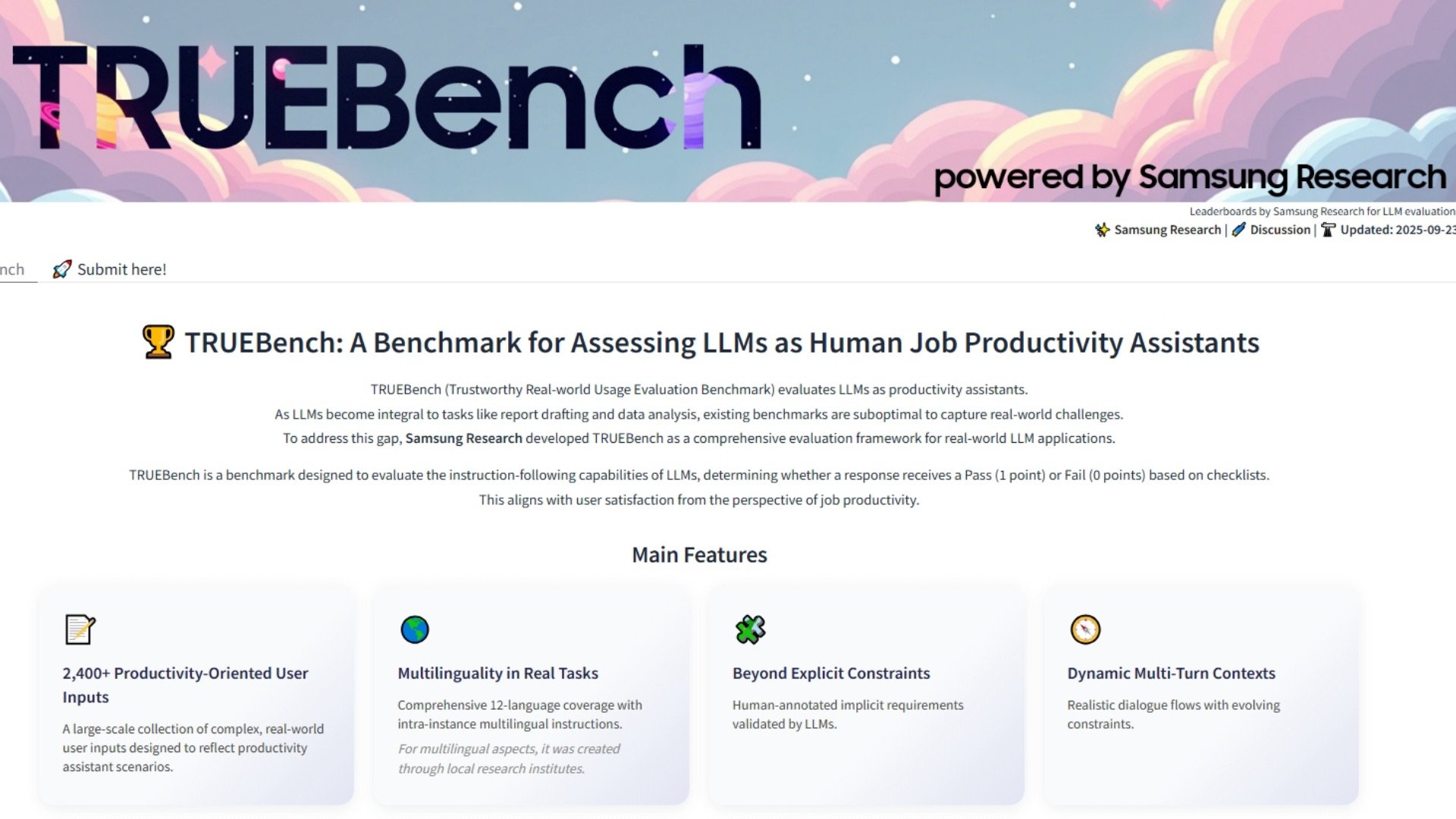
一个模型要想通过测试,就必须满足测试中的每一个必要条件,包括隐含的条件,这些条件反映了一个合理的人会期望什么,即使这些条件没有明确说明。这种 "全有或全无 "的方法降低了结果的宽容度,但也使结果更接近于你决定一项输出是否真正有用的方式。三星通过将人工输入与人工智能检查相结合的方式创建了这些规则。人类注释者起草初始条件,人工智能标记矛盾或不一致之处,然后人类再次完善框架,最后将其锁定。一旦最终确定,评估就可以通过自动人工智能评分进行大规模运行。
三星 还通过 Hugging Face 公开了数据集、排行榜和输出统计数据。你可以直接比较多达五个模型,看看它们的结果如何。这种透明度让开发人员、研究人员和用户可以对基准进行检验,而不是简单地相信三星的说法。
不过,该基准并不完美,因为规则的设定总会存在一定程度的偏差,而且要求在每个条件下都完全成功意味着部分但仍有帮助的答案会被记为失败。语言支持比大多数现有测试更进一步,但性能难免会有差异,尤其是在缺乏训练数据的语言中。测试集还偏重于一般的商业任务,因此高度专业化的领域,如法律、医学或科学研究可能无法完全体现。
资料来源

