根据最新学术研究,一种语言在法律硕士考试中击败英语和汉语,令人惊讶
一项新的多语言研究对大型语言模型如何处理长文档进行了评估,并得出了一个意想不到的信息:当上下文窗口扩展到 64,000 个标记或更多时,波兰语的准确率最高,而不是英语或汉语。这些发现来自OneRuler 基准,该基准是在 COLM 2025 论文中提出的。中介绍的 OneRuler 基准,该基准测试了 26 种语言的检索和聚合任务。
研究人员比较了多种上下文长度下的模型准确率,发现一旦序列变长,准确率就会发生明显的变化。根据结果图表(第 6 页),波兰语在长语境规模下以 88% 的平均准确率领先于所有语言。英语跌至第六位,而汉语排名倒数第四。
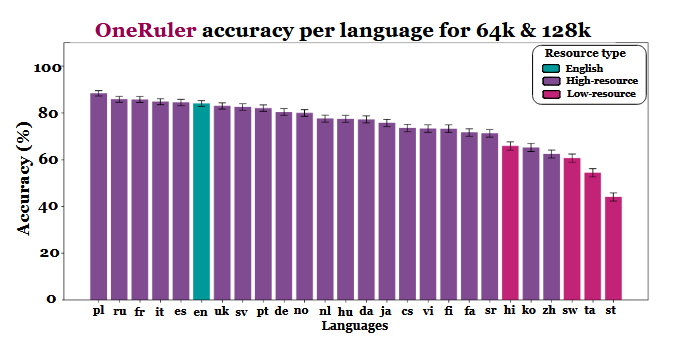
研究暗示,这种差异可能与标记化效率和基于脚本的差异有关,而不仅仅是训练数据量。使用拉丁字母的语言,如波兰语、法语和西班牙语,一直比使用对数或abugida书写系统的语言表现更好。汉语、韩语、泰米尔语和其他语言即使在较短的语境中也只表现出中等准确度(随着序列变长,准确度进一步下降)。这种与预期排名完全相反的情况非常有趣,因为大多数广泛使用的 LLM 主要是在英语较多的数据集上进行训练的。然而,论文的结果表明,一旦模型必须搜索、召回或总结深藏在长文档中的信息,语言的结构方面就会优先于数据集的普遍性。
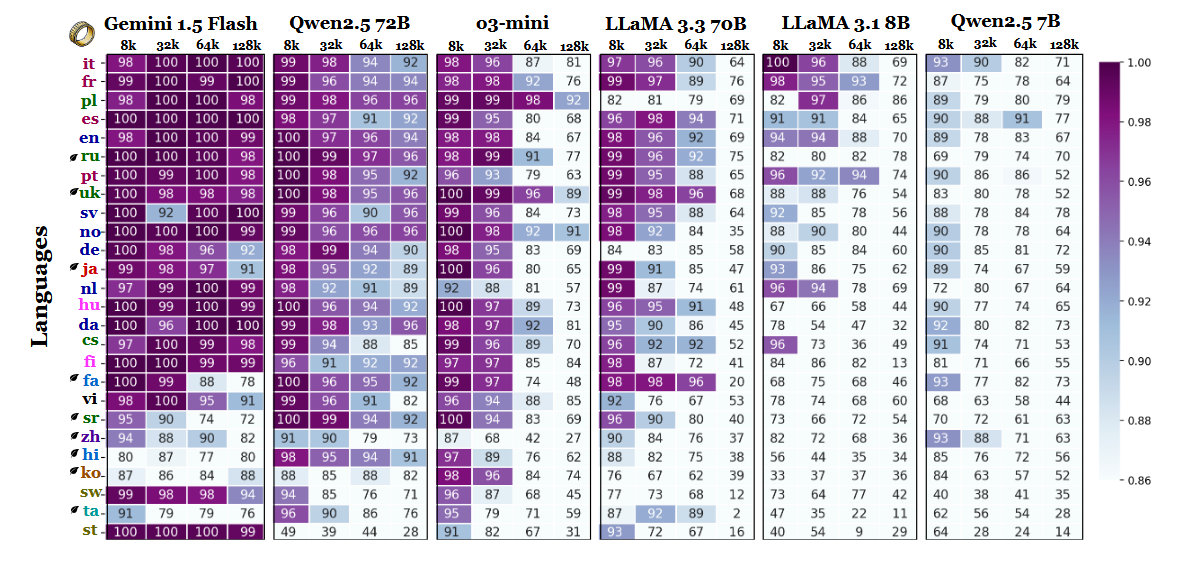
基准测试中的其他发现也支持这种解释。随着上下文范围的扩大,最强语言和最弱语言之间的性能差距急剧拉大--从 8,000 字节时的 11% 到 128,000 字节时的 34%。研究中的另一个细节显示了这些测试对微小指令变化的敏感性。例如,如果目标字符串不存在,只允许模型回答 "无",就会导致 128k 字节的英语准确率下降 32%,如第 2 页所示。
虽然该基准测试也对模型系列进行了比较,但结果表明,长语境评估不能仅仅依赖英语测试,如果忽略脚本和标记化效应,跨语言的性能概括可能会产生误导。随着上下文窗口的增大,语言差异的重要性也在增加,而不是减少--一旦序列长度攀升到数万时,英语在 LLM 基准中的主导地位可能不再具有代表性。
资料来源

